Message throughput per second
Publishing ten thousand small messages to xmlBlaster, which updates the messages
to one subscribed client. The published and updated messages are acknowledged:
672 messages per second
on a AMD-K7 600 MHz, both client and server on the same machine running Linux 2.4.4 using JRockit 3.1 JVM with JacORB 1.3.30 CORBA lib.
The java virtual machine options are set to -Xms18M -Xmx32M: java -server -Xms18M -Xmx32M org.xmlBlaster.Main java -Xms18M -Xmx32M org.xmlBlaster.test.stress.LoadTestSub
The socket connections eat up most of the cpuload, thereafter XML parsing
is expensive. The xmlBlaster code itself only consumes little of the
processing time.
Green threads and native threads have more or less the same performance.
For other java virtual machines see the Volano Report.
When running the above test with different protocols, JacORB seems to
beat the others:
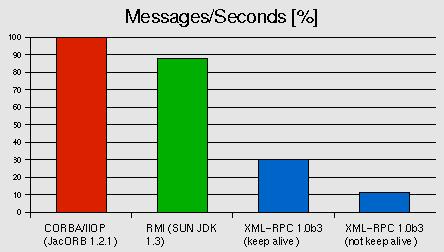
Fig: Performance comparison of different protocols used in xmlBlaster, message throughput in percent to the winner.
Number of simultaneous clients
Running this test:
java -Xms10m -Xmx220m org.xmlBlaster.Main -info false java -Xms10m -Xmx220m org.xmlBlaster.test.qos.TestSubManyClients -numClients 10000
Running xmlBlaster and "TestSubManyClients" on the same machine.
There are in this example 10-thousand clients which login to xmlBlaster
simultaneously.
For RMI, every login consums ~9 kByte on the server,
for CORBA ~11 kByte per login.
All 10.000 clients subscribe to a message.
A publisher client then publishes this message which is
updated to all 10.000 clients.
With CORBA, 435 messages/sec are delivered
on a AMD-K7 600 MHz, both client and server on the same machine running Linux 2.2.16 using JDK 1.3 (IBMJava2-13) with JacORB 1.2.2 CORBA lib.
With POA/CORBA the server request handling is finegrained adjustable, here we used 'one thread per request' policy (using a thread pool).
With RMI no server policy is adjustable, looking into Suns java code shows us, that they use 'one thread per request' policy as well (but this is nowhere specified).
In both cases, the number of clients is only limited by the amount of memory (RAM) you have on your server.Delivering messages in "burst mode"
The "burst mode" collects messages over a certain time and sends them in a bulk.
Collecting 10-thousand messages and publishing them in burst mode, with no client update. CORBA resulted in 2647 messages/sec RMI resulted in 2763 messages/sec. XMLRPC reached 1431 messages/sec. on a 600MHz AthlonXmlBlaster does XML parsing for each message.
Message latency
Data about the brutto round trip latency of a message publish/update.
The following results are for one round trip including publish -> processing in xmlBlaster -> update -> parsing in client on a 600 MHz AMD Linux.- CORBA in intranet: ~ 6 milliseconds
- XMLRPC in intranet: ~ 16 milliseconds
- CORBA over internet: ~ 105 milliseconds
- XMLRPC over internet: ~ 320 milliseconds
xmlBlaster/demo/javaclients/Latency.java
Try a traceroute 'desthost' to compare the MoM based round trip with the raw tcp/ip roundtrip times.
Message throughput per second native compiled
The same scenario as above but compiled with TowerJ 3.5.0 native compiler on Linux:20% - 35% performance increase compared to JDK 1.2.2
It is possible that these number are higher in other test scenarios since this test case cycles mainly in TCP/IP calls.
See the TowerJ homepage for more informations, and thanks to Object Tools for their support.
Required Memory (RAM / message)
Publishing one thousand different messages with only 8 bytes of content and with a relatively small meta data key to xmlBlaster (x86 PC):Approximately 2.4 KByte RAM per messageNote this is the raw memory consumption of xmlBlaster to handle a single message. Your message content (for example a gif picture or some text) must be added to this value. The message content may as well be a pointer to some bigger file to avoid RAM consumption.
XSL and XML performance
As XSL processor we use XT written by James Clark.The XML engine is currently Crimson from Sun for JDK <= 1.4 and since JDK 1.5 the natively delivered XML parser
This is not one of the fastest combinations today, but there may be the option to switch to another parser in future xmlBlaster releases.
See the performance overview, copied from the XSL mailing list for coding hints.
Please visit XSLBench, the performance benchmark of XSLT processors for further informations.
This performance test from Kuznetsov and Dolph shows that XT is still superb performing.
Java XML Benchmark Results
Here is a comparison of SAX2 versus pull parser performance and here another interesting one.
The Java virtual machine
The used Java virtual machines have a high impact on the overall performance.The Volano Report gives a good overview about current implementations, as a result we may run some tests with the IBM virtual machine in future.
See Suns comparison as well.